教育改变生活
标题:
【数据结构】双链表
[打印本页]
作者:
wander
时间:
2023-6-12 16:27
标题:
【数据结构】双链表
本帖最后由 wander 于 2023-6-12 16:29 编辑
虽然使用单链表能 100% 解决逻辑关系为 "一对一" 数据的存储问题,但在解决某些特殊问题时,单链表并不是效率最优的存储结构。比如说,如果算法中需要大量地找某指定结点的前趋结点,使用单链表无疑是灾难性的,因为单链表更适合 "从前往后" 找,而 "从后往前" 找并不是它的强项。
为了能够高效率解决类似的问题,可以采用双链表来实现。
从名字上理解双向链表,即链表是 "双向" 的,
指的是各节点之间的逻辑关系是双向的,但通常头指针只设置一个,除非实际情况需要。
如图 1 所示:
图 1 双向链表结构示意图
从图 1 中可以看到,双向链表中各节点包含以下 3 部分信息(如图 2 所示):
指针域
:用于指向当前节点的直接前驱节点;
数据域
:用于存储数据元素。
指针域
:用于指向当前节点的直接后继节点;
图 2 双向链表的节点构成
因此,双链表的节点结构为:
typedef
struct
line
{
struct
line
*
prior
;
//指向直接前趋
int
data
;
struct
line
*
next
;
//指向直接后继
}
line
;
双向链表的创建
同单链表相比,双链表仅是各节点多了一个用于指向直接前驱的指针域。因此,我们可以在单链表的基础轻松实现对双链表的创建。
需要注意的是,与单链表不同,双链表创建过程中,每创建一个新节点,都要与其前驱节点建立两次联系,分别是:
将新节点的 prior 指针指向直接前驱节点;
将直接前驱节点的 next 指针指向新节点;
创建双向链表的代码:
line
*
initLine
(
line
*
head
)
{
head
=(
line
*)
malloc
(
sizeof
(
line
));
//创建链表第一个结点(首元结点)
head
->
prior
=
NULL
;
head
->
next
=
NULL
;
head
->
data
=
1
;
line
*
list
=
head
;
for
(
int
i
=
2
;
i
<=
3
;
i
++)
{
//创建并初始化一个新结点
line
*
body
=(
line
*)
malloc
(
sizeof
(
line
));
body
->
prior
=
NULL
;
body
->
next
=
NULL
;
body
->
data
=
i
;
list
->
next
=
body
;
//直接前趋结点的next指针指向新结点
body
->
prior
=
list
;
//新结点指向直接前趋结点
list
=
list
->
next
;
}
return
head
;
}
双向链表添加节点
根据数据添加到双向链表中的位置不同,可细分为以下 3 种情况:
添加至表头
将新数据元素添加到表头,只需要将该元素与表头元素建立双层逻辑关系即可。
换句话说,假设新元素节点为 temp,表头节点为 head,则需要做以下 2 步操作即可:
temp->next=head; head->prior=temp;
将 head 移至 temp,重新指向新的表头;
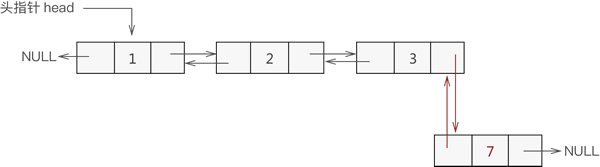
例如,将新元素 7 添加至双链表的表头,则实现过程如图 2 所示:
图 2 添加元素至双向链表的表头
添加至表的中间位置
同单链表
添加数据类似,双向链表中间位置添加数据需要经过以下 2 个步骤,如图 3 所示:
新节点先与其直接后继节点建立双层逻辑关系;
新节点的直接前驱节点与之建立双层逻辑关系;
图 3 双向链表中间位置添加数据元素
添加至表尾
与添加到表头是一个道理,实现过程如下(如图 4 所示):
找到双链表中最后一个节点;
让新节点与最后一个节点进行双层逻辑关系;
图 4 双向链表尾部添加数据元素
因此,我们可以试着编写双向链表添加数据的代码,参考代码如下:
line
*
insertLine
(
line
*
head
,
int
data
,
int
add
)
{
//新建数据域为data的结点
line
*
temp
=(
line
*)
malloc
(
sizeof
(
line
));
temp
->
data
=
data
;
temp
->
prior
=
NULL
;
temp
->
next
=
NULL
;
//插入到链表头,要特殊考虑
if
(
add
==
1
)
{
temp
->
next
=
head
;
head
->
prior
=
temp
;
head
=
temp
;
}
else
{
line
*
body
=
head
;
//找到要插入位置的前一个结点
for
(
int
i
=
1
;
i
<
add
-1
;
i
++)
{
body
=
body
->
next
;
}
//判断条件为真,说明插入位置为链表尾
if
(
body
->
next
==
NULL
)
{
body
->
next
=
temp
;
temp
->
prior
=
body
;
}
else
{
body
->
next
->
prior
=
temp
;
temp
->
next
=
body
->
next
;
body
->
next
=
temp
;
temp
->
prior
=
body
;
}
}
return
head
;
}
双向链表删除节点
双链表删除结点时,只需遍历链表找到要删除的结点,然后将该节点从表中摘除即可。
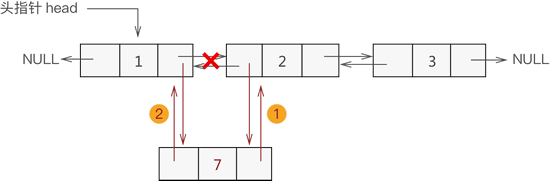
例如,从图 1 基础上删除元素 2 的操作过程如图 5 所示:
图 5 双链表删除元素操作示意图
双向链表删除节点的代码如下:
//删除结点的函数,data为要删除结点的数据域的值
line
*
delLine
(
line
*
head
,
int
data
)
{
line
*
temp
=
head
;
//遍历链表
while
(
temp
)
{
//判断当前结点中数据域和data是否相等,若相等,摘除该结点
if
(
temp
->
data
==
data
)
{
temp
->
prior
->
next
=
temp
->
next
;
temp
->
next
->
prior
=
temp
->
prior
;
free
(
temp
);
return
head
;
}
temp
=
temp
->
next
;
}
printf
(
"链表中无该数据元素"
);
return
head
;
}
双向链表查找节点
通常,双向链表同单链表一样,都仅有一个头指针。因此,双链表查找指定元素的实现同单链表类似,都是从表头依次遍历表中元素。
实现代码为:
//head为原双链表,elem表示被查找元素
int
selectElem
(
line
*
head
,
int
elem
)
{
//新建一个指针t,初始化为头指针 head
line
*
t
=
head
;
int
i
=
1
;
while
(
t
)
{
if
(
t
->
data
==
elem
)
{
return
i
;
}
i
++;
t
=
t
->
next
;
}
//程序执行至此处,表示查找失败
return
-
1
;
}
双向链表更改节点
更改双链表中指定结点数据域的操作是在查找的基础上完成的。实现过程是:通过遍历找到存储有该数据元素的结点,直接更改其数据域即可。
实现此操作的 C 语言实现代码如下:
//更新函数,其中,add 表示更改结点在双链表中的位置,newElem 为新数据的值
line
*
amendElem
(
line
*
p
,
int
add
,
int
newElem
)
{
line
*
temp
=
p
;
//遍历到被删除结点
for
(
int
i
=
1
;
i
<
add
;
i
++)
{
temp
=
temp
->
next
;
}
temp
->
data
=
newElem
;
return
p
;
}
欢迎光临 教育改变生活 (http://bbs.goldoar.com/)
Powered by Discuz! X3.2