|
这次,锐龙一直以来可以说唯一弱势的单核心/游戏性能终于不再是短板,一举实现了对Intel的反超,而且还是在制造工艺维持7nm工艺完全不变的前提下做到的,全新设计的Zen3架构可以说功不可没,这也是Zen诞生以来最大规模的变革。

今天,我们就好好聊一聊Zen3架构的革新之处。 当然了,处理器架构设计是极为高深的学问,我们不可能讲得多么深入、专业,就说说一些比较表层和便于理解的东西,看看如此逆天的性能飞跃究竟如何而来。

首先,做任何事都要有目标,设计一个处理器架构更是如此。Zen3的目标就有三个: 一是提升单线程性能,专业名词叫IPC(每时钟周期指令数),毕竟之前几代一直追求多核心为主,是时候把单核性能提升到足够的高度了,不然始终是瘸着脚走路,缺乏长久竞争力。 二是在维持8核心CCD模块的前提下,统一核心与缓存,提升彼此通信效率,降低延迟。 三是继续提高能效比,性能提升的同时功耗不能失控。
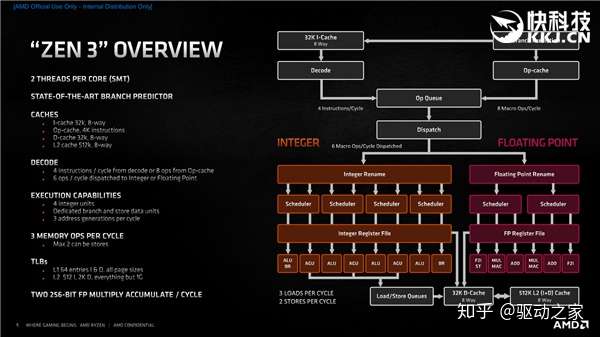
为此,Zen3架构对于所有模块都进行了翻新,前端、预取、解码、执行、整数、浮点、载入、存储、缓存等等,每个环节都是焕然一新。 首先,Zen3设计了一个堪称艺术级的分支预测器,它之后有两条通道将指令送入队列,然后进行分派,一是8路关联的32KB一级指令缓存和x86解码器,二是4K指令的操作缓存(Op-cache)。 x86解码器的限制是每个时钟周期只能处理最多4条指令,但如果是熟悉的指令,就可以放入操作缓存,每个周期就能处理8条,二者结合指令分发效率就大大提升,相比于Zen2直接上升了一个档次。 指令分派之后就来到执行引擎阶段,分为整数、浮点两大部分,每个时钟周期可以向它们分派6条指令。 其中,整数单元还是4个,但更加分散,并增加了一个单独的分支与数据存储单元,提升吞吐量,每时钟周期可以生成3个地址。 浮点方面则分为六条流水线,进一步提升吞吐量和效率。 内存方面,每时钟周期可以执行3个载入,或者1个载入加2个存储,再次提升吞吐量,并且可以更灵活地处理不同工作负载。
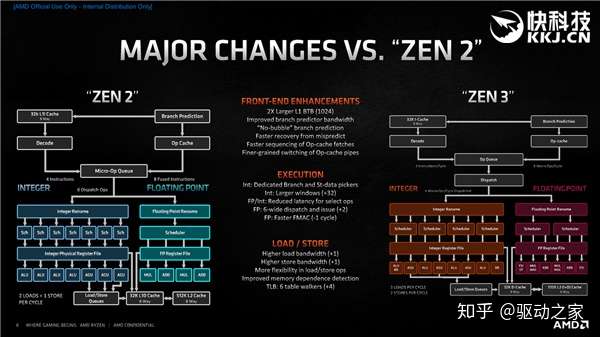
单纯说Zen3可能感觉不到什么,那就对比一下Zen2,变化太多还是捡最核心的说。 前端方面,主要有容量翻番的L1 BTB、更大的分支预测器带宽、更快的预测错误恢复、更快的操作缓存拾取、更精细的操作缓存流水线切换,等等。 执行引擎方面,主要有独立的分支与数据存储单元、更大的整数窗口、更低的特定整数/浮点指令延迟、6宽度拾取与分发、更宽的浮点分派、更快的浮点FMAC(乘法累加器),等等。 载入/存储方面,主要有更高的载入带宽(2个变3个)、更高的存储带宽(1个变2个)、更灵活的载入/存储指令、更好的内存依赖检测,等等。
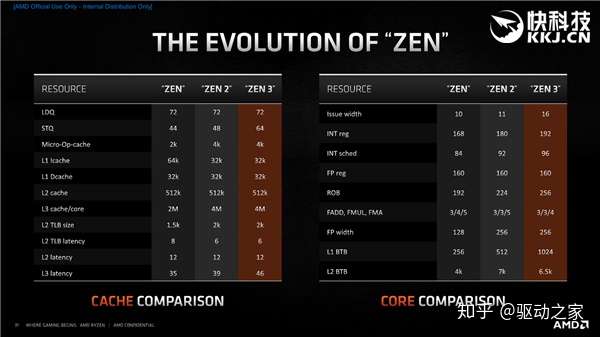
以上是Zen、Zen2、Zen3三代架构在核心、缓存一些关键指标上的变化。乍一看,Zen3变化的力度似乎不如Zen2,但一则这些数字不能完全反应更深层次的变化,二则Zen3在关键指标上更有突破,比如说分发宽度从10/11一跃来到16,执行效率提升可不止一点半点。
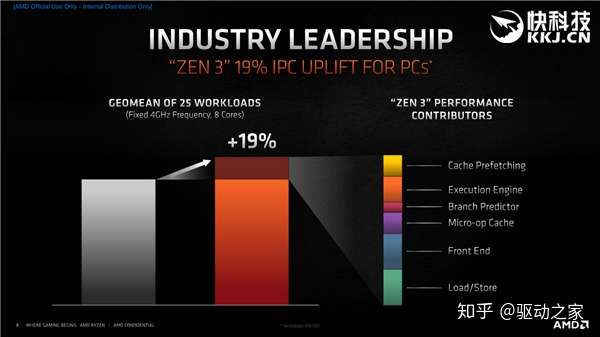
正是基于这些改进,Zen3架构的IPC提升了多达19%,来自前端、载入/存储、执行引擎、缓存预取、微操作缓存、分支预测等部分的合力贡献。 那么大家可能会疑惑了,19%这个数字怎么来的?
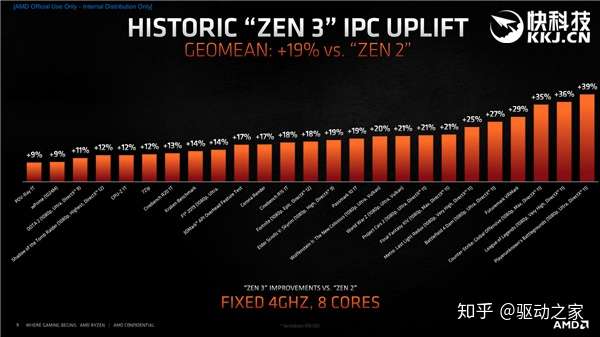
说起来也简单,Zen3、Zen2架构都固定在8核心、4GHz频率,然后对比不同应用的性能变化,最后综合而来。 不同工作负载的提升幅度当然不尽相同,变化最大的是锐龙之前的弱项网游,吃鸡、LOL、CSGO这些提升了多达35-39%,再加上频率提升等,最终大家就看到了锐龙5000在网游里边翻天覆地的变化。 事实上,提升幅度超过19%平均水平的,基本都是游戏,也正因为如此,锐龙5000才在游戏性能上夺走了Intel的最后一处阵地,有资格说自己是最好的游戏处理器。 提升幅度相对较小的是一些基准性质项目和一些难以深度优化的游戏,尤其是单线程性能,比如POV-Ray 9%、CPU-Z 12%、CineBench R20 13%,CineBench R15 18%,但即便如此大家也看到了非常明显的实际性能提升,这可比某几代酷睿每次最多5%左右的变化良心太多了。 如果你觉得前边讲的架构不过瘾,想了解更深入,接下来我们就拆解成不同模块,单独来看一看它们的变化。
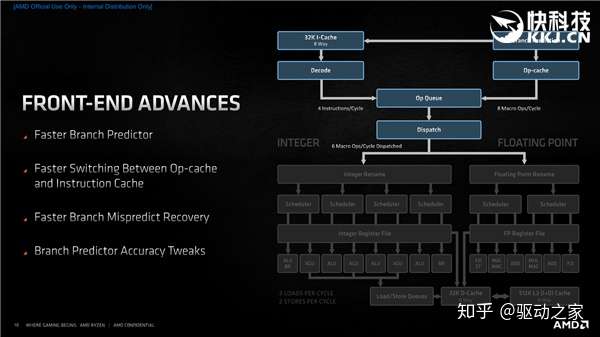
前端部分,Zen3打造了一个更快的分支预测器,可以在每个时钟周期内处理更多指令,同时在操作缓存、指令缓存之间切换更加快速,应付不同工作负载更加灵活高效。 当然,分支预测不可能百分之百准确,都是有概率的,有时候会预测错误,这时候的关键就是能不能快速恢复,Zen3就大大降低了这时候的延迟,可以快速回到正轨,分支预测的精度也得到提升。
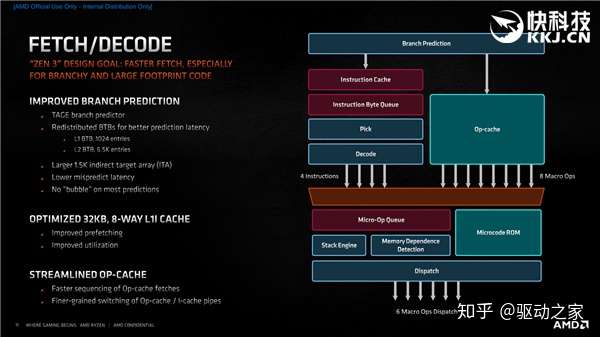
拾取与解码部分,这里可以看到分支预测器的更多细节,尤其是精度提升是怎么来的,比如分支目标缓冲重新设计、L1 B2B容量翻倍、L2 B2B重新组织、间接目标阵列(ITA)增大、流水线缩短、错误预测延迟降低等等。 同时,32KB 8路关联的一级指令缓存进行了优化,从而改进预取能力和利用率。 操作缓存也更加精炼,队列拾取效率更高,操作缓存与指令缓存流水线的切换也更加自如。
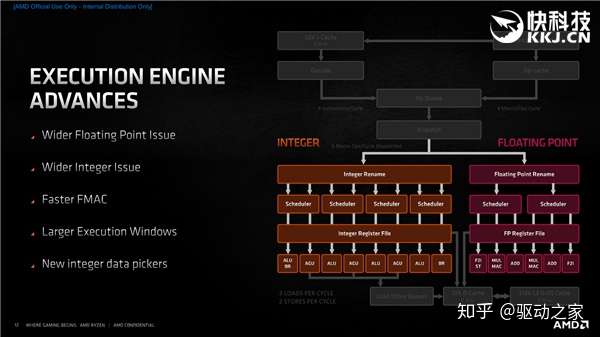
执行引擎方面,增加了浮点和整数分发宽度,降低了FMAC延迟,还增大了执行窗口。
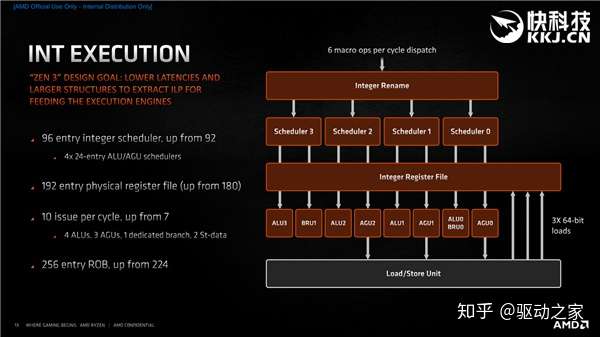
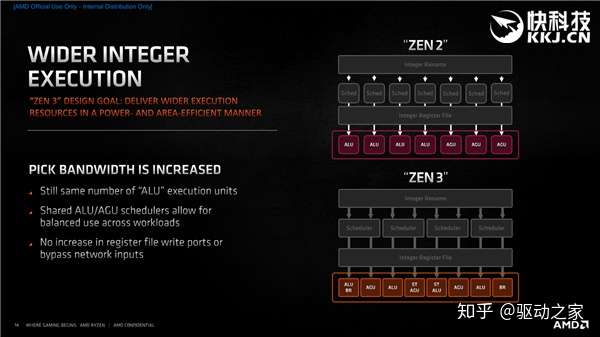
整数执行方面,整数调度器节点从92个增至96个(4×24分布),用来重命名逻辑寄存器以提升乱序执行效率的物理寄存器文件也从180个增至192个。 每时钟周期的分发也从7个增至10个,包括4个ALU(算术逻辑单元)、3个AGU(地址生成单元)、1个分支单元、2个存储数据单元。 此外,记录器缓冲(ROB)所保存的x86指令也从224个增至256个。 Zen3里的整数单元没变还是4个,但共享了ALU、AGU调度器,应对不同负载时更加均衡。
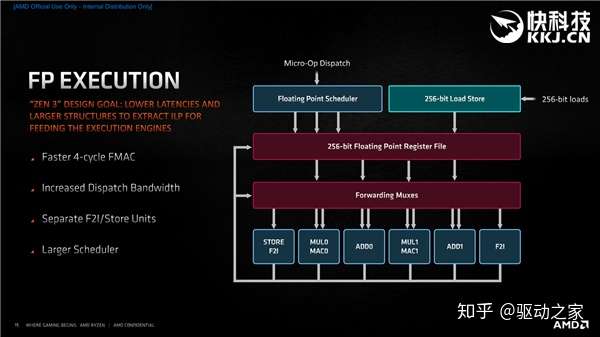
浮点执行方面,浮点单元增至6条流水线意味着可以一次性分派6个微操指令,同时以前兼顾负责存储与浮点寄存器文件的MUL乘法、ADD加法整数单元现在改为独立流水线,需要的时候可以更好地处理真正的MUL、ADD指令。 另外还有更快的4周期FMAC、分离的F2I与存储单元、更大的调度器。
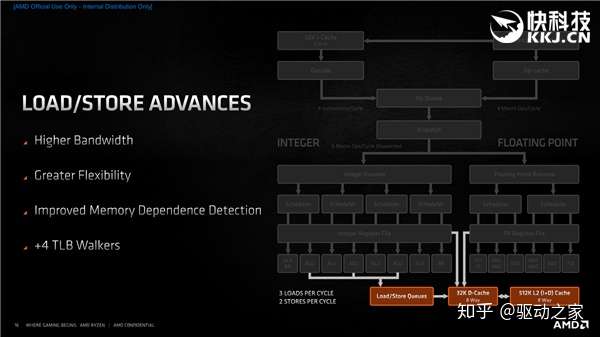
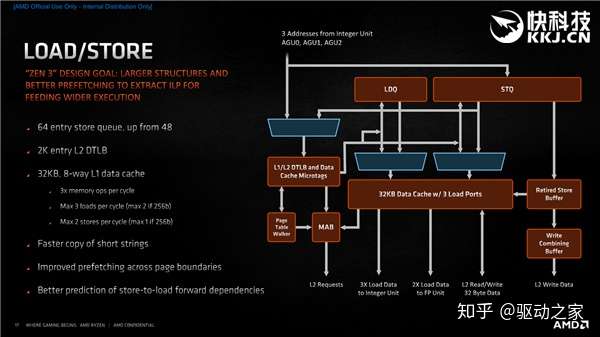
载入/存储方面,存储队列节点从48个增至64个,同时增大了与32KB一级指令缓存之间的带宽,每时钟周期可以执行3个载入,或者2个浮点与1个存储,另外还改进了预取算法,以更好地利用容量翻番的三级缓存。 接下来我们回到“高级”层面,看看Zen3在核心与缓存方面的设计。
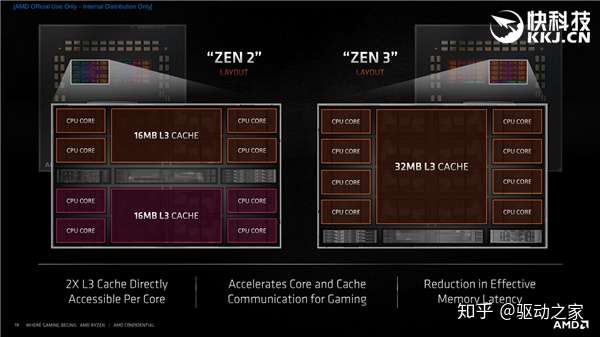
这张CDD核心与缓存布局图大家很熟悉了。Zen2、Zen3的每个CCD都是8个物理核心、32MB三级缓存,但前者是隔离的两部分,每4个核心共享一半的16MB三级缓存,而后者是完整的一部分,所有8个核心共享所有32MB三级缓存,等于每个核心可获取的三级缓存容量直接翻了一番。 Zen2上边,如果某个核心需要的指令、数据在非直接共享的另一半三级缓存里,那么就要绕一个圈,延迟自然大大增加,现在可以直接一步到位了,当第一个核心需要的数据在第八个核心里的时候,也可以直接在CCX内部快速获取到。

再看缓存细节。一二三级容量都没变,但效率高得多,比如32KB一级指令缓存支持32bit拾取,32KB一级数据缓存支持最多3个载入、2个存储,512KB二级缓存速度也更快了。 三级缓存容量增大、访问统一后,可以完全保存二级缓存里被丢弃出来的牺牲品缓存(victim cache),相当于一个备份,因为它们被再次访问的概率很高,这样无论哪个核心再次需要,都可以直接从缓存从交换获取。 另外,每个核心从二级缓存到三级缓存允许64个命中失败,从三级缓存到内存则允许192个命中失败。
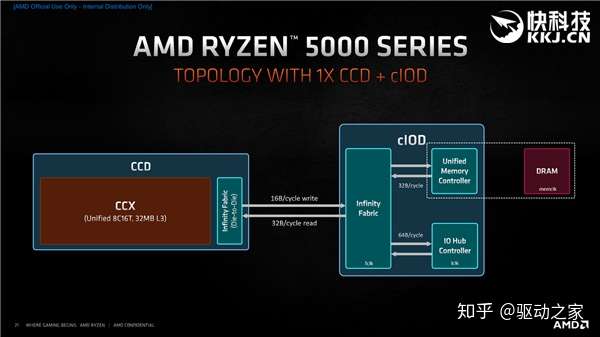
锐龙5000系列让然延续chiplet小芯片设计,一个或两个CCD Die搭配一个IOD(负责内存控制器和输入输出),但是由于每个CCD里只有统一的一个CCX而不再是独立的两个,CCD与IOD、内存之间的连接通信也更加一致、高效。
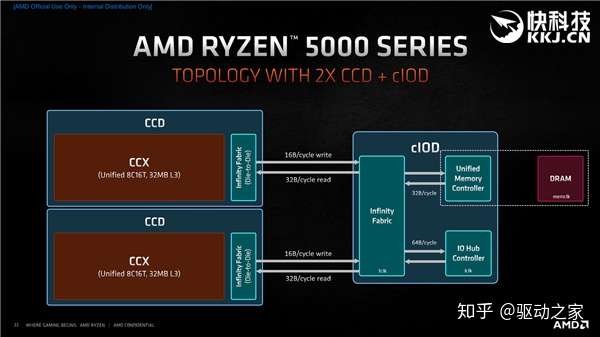
两个CCD搭配一个IOD的时候,带宽是相同的,也是同样的一致性系统。

这时候也再次体现了chiplet小芯片设计的好处,可以轻松做到16核心,可以不换布局和平台就升级到Zen3架构,一切都在封装内部进行。

安全方面,Zen3重点增加了控制流强制技术(CET),Intel此前已支持。它引入了影子堆栈(shadow stack),只包含返回地址并且存储在系统内存中,同时受到处理器内存管理模块的保护,如果有恶意代码利用漏洞村改堆栈,在造成伤害之前就能被发现并阻止。

指令集方面,Zen3增加了MPK,也就是内存保护密钥,可以由软件更高效地改变数据读写权限,另外VAES、VPCLMULQD指令增加支持AVX2。
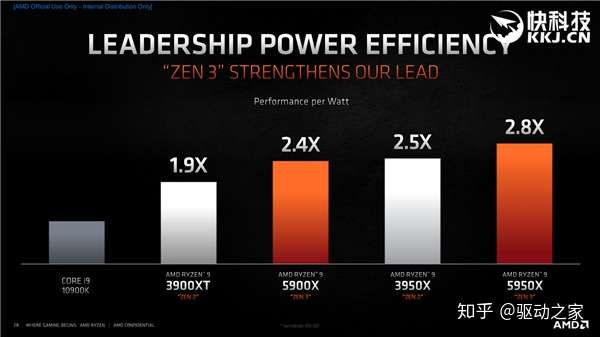
最后说说能效,按照官方说法Zen3架构的锐龙9 5950X、锐龙9 5900X相比于i9-10900K分别达到了2.8倍、2.4倍,而对比Zen2架构的锐龙9 3950X、锐龙9 3900XT也分别提高了12%、26%,从而做到了性能更好,但功耗不增加。

总之,Zen3顺利实现了预期目标,包括IPC大幅提升(平均19%)、延迟大幅降低(统一8核心与32MB三级缓存)、内存访问大幅加速(三级缓存直接访问翻倍)、频率大幅提高(最高加速4.9GHz)、能效大幅改进(最高2.8倍)、游戏帧率大幅增长(1080p下平均约26%)。

AMD Zen的下一站将是Zen 4,会同时搭配更先进的5nm工艺,目前正在设计中,一切按计划推进,看时间表应该会在2022年上半年推出。
| 















 发表于 2021-3-25 16:23:44
发表于 2021-3-25 16:23:44

 收藏
收藏

 闽公网安备35010302000916号
闽公网安备35010302000916号