|
线程安全性 在多线程使用场景中,应该尽量避免使用线程不安全的HashMap,而使用线程安全的ConcurrentHashMap。那么为什么说HashMap是线程不安全的,下面举例子说明在并发的多线程使用场景中使用HashMap可能造成死循环。代码例子如下(便于理解,仍然使用JDK1.7的环境): - public class HashMapInfiniteLoop {
- private static HashMap<Integer,String> map = new HashMap<Integer,String>(2,0.75f);
- public static void main(String[] args) {
- map.put(5, "C");
- new Thread("Thread1") {
- public void run() {
- map.put(7, "B");
- System.out.println(map);
- };
- }.start();
- new Thread("Thread2") {
- public void run() {
- map.put(3, "A);
- System.out.println(map);
- };
- }.start();
- }
- }
其中,map初始化为一个长度为2的数组,loadFactor=0.75,threshold=2*0.75=1,也就是说当put第二个key的时候,map就需要进行resize。 通过设置断点让线程1和线程2同时debug到transfer方法(3.3小节代码块)的首行。注意此时两个线程已经成功添加数据。放开thread1的断点至transfer方法的“Entry next = e.next;” 这一行;然后放开线程2的的断点,让线程2进行resize。结果如下图。 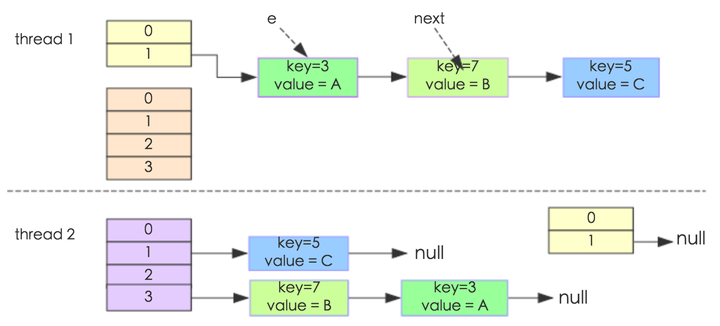 注意,Thread1的 e 指向了key(3),而next指向了key(7),其在线程二rehash后,指向了线程二重组后的链表。 线程一被调度回来执行,先是执行 newTalbe = e, 然后是e = next,导致了e指向了key(7),而下一次循环的next = e.next导致了next指向了key(3)。 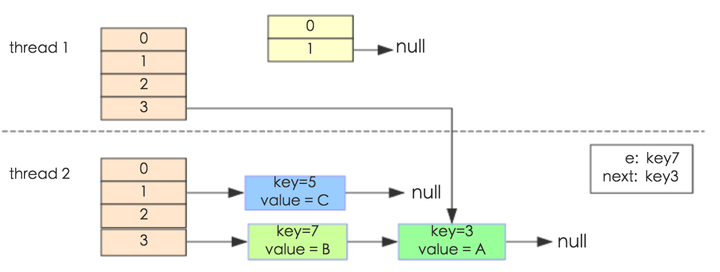 e.next = newTable 导致 key(3).next 指向了 key(7)。注意:此时的key(7).next 已经指向了key(3), 环形链表就这样出现了。 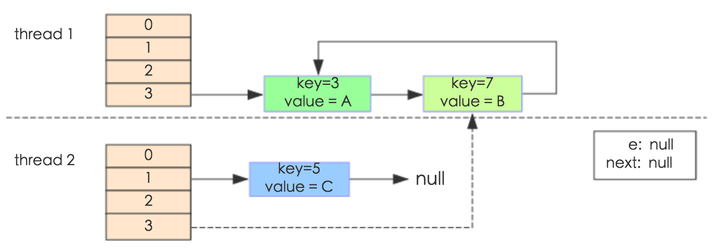 于是,当我们用线程一调用map.get(11)时,悲剧就出现了——Infinite Loop。 JDK1.8与JDK1.7的性能对比HashMap中,如果key经过hash算法得出的数组索引位置全部不相同,即Hash算法非常好,那样的话,getKey方法的时间复杂度就是O(1),如果Hash算法技术的结果碰撞非常多,假如Hash算极其差,所有的Hash算法结果得出的索引位置一样,那样所有的键值对都集中到一个桶中,或者在一个链表中,或者在一个红黑树中,时间复杂度分别为O(n)和O(lgn)。 鉴于JDK1.8做了多方面的优化,总体性能优于JDK1.7,下面我们从两个方面用例子证明这一点。 Hash较均匀的情况为了便于测试,我们先写一个类Key,如下: - class Key implements Comparable<Key> {
- private final int value;
- Key(int value) {
- this.value = value;
- }
- @Override
- public int compareTo(Key o) {
- return Integer.compare(this.value, o.value);
- }
- @Override
- public boolean equals(Object o) {
- if (this == o) return true;
- if (o == null || getClass() != o.getClass())
- return false;
- Key key = (Key) o;
- return value == key.value;
- }
- @Override
- public int hashCode() {
- return value;
- }
- }
这个类复写了equals方法,并且提供了相当好的hashCode函数,任何一个值的hashCode都不会相同,因为直接使用value当做hashcode。为了避免频繁的GC,我将不变的Key实例缓存了起来,而不是一遍一遍的创建它们。代码如下: - public class Keys {
- public static final int MAX_KEY = 10_000_000;
- private static final Key[] KEYS_CACHE = new Key[MAX_KEY];
- static {
- for (int i = 0; i < MAX_KEY; ++i) {
- KEYS_CACHE[i] = new Key(i);
- }
- }
- public static Key of(int value) {
- return KEYS_CACHE[value];
- }
- }
现在开始我们的试验,测试需要做的仅仅是,创建不同size的HashMap(1、10、100、......10000000),屏蔽了扩容的情况,代码如下: - static void test(int mapSize) {
- HashMap<Key, Integer> map = new HashMap<Key,Integer>(mapSize);
- for (int i = 0; i < mapSize; ++i) {
- map.put(Keys.of(i), i);
- }
- long beginTime = System.nanoTime(); //获取纳秒
- for (int i = 0; i < mapSize; i++) {
- map.get(Keys.of(i));
- }
- long endTime = System.nanoTime();
- System.out.println(endTime - beginTime);
- }
- public static void main(String[] args) {
- for(int i=10;i<= 1000 0000;i*= 10){
- test(i);
- }
- }
在测试中会查找不同的值,然后度量花费的时间,为了计算getKey的平均时间,我们遍历所有的get方法,计算总的时间,除以key的数量,计算一个平均值,主要用来比较,绝对值可能会受很多环境因素的影响。结果如下:  通过观测测试结果可知,JDK1.8的性能要高于JDK1.7 15%以上,在某些size的区域上,甚至高于100%。由于Hash算法较均匀,JDK1.8引入的红黑树效果不明显,下面我们看看Hash不均匀的的情况。 Hash极不均匀的情况假设我们又一个非常差的Key,它们所有的实例都返回相同的hashCode值。这是使用HashMap最坏的情况。代码修改如下: - class Key implements Comparable<Key> {
- //...
- @Override
- public int hashCode() {
- return 1;
- }
- }
仍然执行main方法,得出的结果如下表所示:  从表中结果中可知,随着size的变大,JDK1.7的花费时间是增长的趋势,而JDK1.8是明显的降低趋势,并且呈现对数增长稳定。当一个链表太长的时候,HashMap会动态的将它替换成一个红黑树,这话的话会将时间复杂度从O(n)降为O(logn)。hash算法均匀和不均匀所花费的时间明显也不相同,这两种情况的相对比较,可以说明一个好的hash算法的重要性。 测试环境:处理器为2.2 GHz Intel Core i7,内存为16 GB 1600 MHz DDR3,SSD硬盘,使用默认的JVM参数,运行在64位的OS X 10.10.1上。小结(1) 扩容是一个特别耗性能的操作,所以当程序员在使用HashMap的时候,估算map的大小,初始化的时候给一个大致的数值,避免map进行频繁的扩容。 (2) 负载因子是可以修改的,也可以大于1,但是建议不要轻易修改,除非情况非常特殊。 (3) HashMap是线程不安全的,不要在并发的环境中同时操作HashMap,建议使用ConcurrentHashMap。 (4) JDK1.8引入红黑树大程度优化了HashMap的性能。 (5) 还没升级JDK1.8的,现在开始升级吧。HashMap的性能提升仅仅是JDK1.8的冰山一角。
| 















 发表于 2021-4-25 16:54:30
发表于 2021-4-25 16:54:30

 收藏
收藏
