|
11.附加题 1:P2P 理论上的加速比 传统的 C/S 模式传输文件,在跑满 Client 带宽的情况下传输一个文件需要耗时 FS/BW,如果有 n 个客户端需要下载文件,那么总耗时是 n*(FS/BW),当然啦,这并不一定是串行传输,可以并行来传输的,这样总耗时也就是 FS/BW 了,但是这需要服务器的带宽是 n 个 client 带宽的总和 n*BW。C/S 模式一个明显的缺点是服务要传输一个文件 n 次,这样对服务器的性能和带宽带来比较大的压力,我可以换下思路,服务器将文件传给其中一个 Client 后,让这些互联的 Client 自己来交互那个文件,那服务器的压力就减少很多了。这就是 P2P 网络的好处,P2P 利用各个节点间的互联,提倡“人人为我,我为人人”。 知道 P2P 传输的好处后,我们来谈下理论上的最大加速比,为了简化讨论,一个简单的网络拓扑图如下,有 4 个相互互联的节点,并且每个节点间的网络带宽是 BW,传输一个大小为 FS 的文件最快的时间是多少呢?假设节点 N1 有个大小为 FS 的文件需要传输给 N2,N3,N4 节点,一种简单的方式就是:节点 N1 同时将文件传输给节点 N2,N3,N4 耗时 FS/BW,这样大家都拥有文件 FS 了。大家可以看出,整个过程只有节点 1 在发送文件,其他节点都是在接收,完全违反了 P2P 的“人人为我,我为人人”的宗旨。那怎么才能让大家都做出贡献了呢?解决方案是切割文件。 [1]首先,节点 N1 文件分成 3 个片段 FS2,FS3,FS4,接着将 FS2 发送给 N2,FS3 发送给 N3,FS4 发送给 N4,耗时 FS/(3*BW); [2]然后,N2,N3,N4 执行“人人为我,我为人人”的精神,将自己拥有的 F2,F3,F4 分别发给没有的其他的节点,这样耗时 FS/(3*BW)完成交换。 于是总耗时为 2FS/(3BW)完成了文件 FS 的传输,可以看出耗时减少为原来的 2/3 了,如果有 n 个节点,那么时间就是原来的 2/(n-1),也就是加速比是 2/(n-1),这就是加速的理论上限了吗?还没发挥最多能量的,相信大家已经看到分割文件的好处了,上面的文件分割粒度还是有点大,以至于,在第二阶段[2]传输过程中,节点 N1 无所事事。为了最大化发挥大家的作用,我们需要将 FS2,FS3,FS4 在进行分割,假设将它们都均分为 K 等份,这样就有 FS21,FS22…FS2K、FS31,FS32…FS3K、FS41,FS42…FS4K,一共 3K 个分段。于是下面就开始进行加速分发: [1]节点 N1 将分段 FS21,FS31,FS41 分别发送给 N2,N3,N4 节点。耗时,FS/(3K*BW) [2]节点 N1 将分段 FS22,FS32,FS42 分别发送给 N2,N3,N4 节点,同时节点 N2,N3,N4 将阶段[1]收到的分段相互发给没有的节点。耗时,FS/(3K*BW)。 [K]节点 N1 将分段 FS2K,FS3K,FS4K 分别发送给 N2,N3,N4 节点,同时节点 N2,N3,N4 将阶段[K-1]收到的分段相互发给没有的节点。耗时,FS/(3K*BW)。[K+1]节点 N2,N3,N4 将阶段[K]收到的分段相互发给没有的节点。耗时,FS/(3K*BW)。于是总的耗时为(K+1) (FS/(3KBW)) = FS/(3BW) +FS/(3KBW),当 K 趋于无穷大的时候,文件进行无限细分的时候,耗时变成了 FS/(3*BW),也就是当节点是 n+1 的时候,加速比是 n。这就是理论上的最大加速比了,最大加速比是 P2P 网络节点个数减 1。 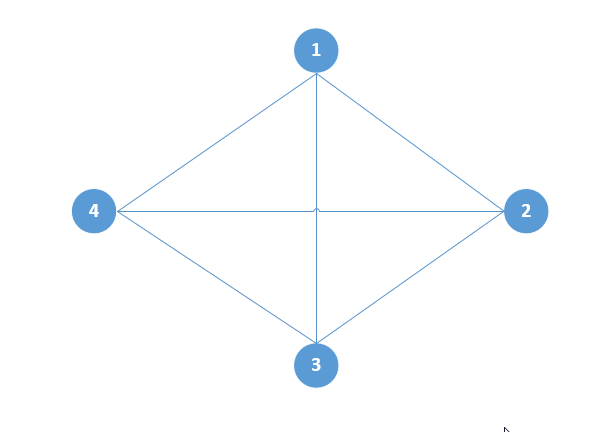 12.附加题 2:系统调用 listen() 的 backlog 参数指的是什么 12.附加题 2:系统调用 listen() 的 backlog 参数指的是什么要说明 backlog 参数的含义,首先需要说一下 Linux 的协议栈维护的 TCP 连接的两个连接队列:[1]SYN 半连接队列;[2]accept 连接队列。 [1]SYN 半连接队列:Server 端收到 Client 的 SYN 包并回复 SYN,ACK 包后,该连接的信息就会被移到一个队列,这个队列就是 SYN 半连接队列(此时 TCP 连接处于 非同步状态 ) [2]accept 连接队列:Server 端收到 SYN,ACK 包的 ACK 包后,就会将连接信息从[1]中的队列移到另外一个队列,这个队列就是 accept 连接队列(这个时候 TCP 连接已经建立,三次握手完成了)。 用户进程调用 accept()系统调用后,该连接信息就会从[2]中的队列中移走。相信不少同学就 backlog 的具体含义进行争论过,有些认为 backlog 指的是[1]和[2]两个队列的和。而有些则认为是 backlog 指的是[2]的大小。其实,这两个说法都对,在 linux kernel 2.2 之前 backlog 指的是[1]和[2]两个队列的和。而 2.2 以后,就指的是[2]的大小,那么在 kernel 2.2 以后,[1]的大小怎么确定的呢?两个队列的作用分别是什么呢? 【1】SYN 半连接队列的作用对于 SYN 半连接队列的大小是由(/proc/sys/net/ipv4/tcp_max_syn_backlog)这个内核参数控制的,有些内核似乎也受 listen 的 backlog 参数影响,取得是两个值的最小值。当这个队列满了,Server 会丢弃新来的 SYN 包,而 Client 端在多次重发 SYN 包得不到响应而返回(connection time out)错误。但是,当 Server 端开启了 syncookies,那么 SYN 半连接队列就没有逻辑上的最大值了,并且/proc/sys/net/ipv4/tcp_max_syn_backlog 设置的值也会被忽略。 【2】accept 连接队列accept 连接队列的大小是由 backlog 参数和(/proc/sys/net/core/somaxconn)内核参数共同决定,取值为两个中的最小值。当 accept 连接队列满了,协议栈的行为根据(/proc/sys/net/ipv4/tcp_abort_on_overflow)内核参数而定。如果 tcp_abort_on_overflow=1,server 在收到 SYN_ACK 的 ACK 包后,协议栈会丢弃该连接并回复 RST 包给对端,这个是 Client 会出现(connection reset by peer)错误。如果 tcp_abort_on_overflow=0,server 在收到 SYN_ACK 的 ACK 包后,直接丢弃该 ACK 包。这个时候 Client 认为连接已经建立了,一直在等 Server 的数据,直到超时出现 read timeout 错误。
| 















 发表于 2020-9-2 16:48:33
发表于 2020-9-2 16:48:33

 收藏
收藏
